すっかり梅雨入りしましたね。
昼休みにグァバジュースを買って、トロピカル気分で働いております、國宗です。
さて、以前岩井さんがアイコンフォントについて記事を書いていましたが、 今回はわかりやすく、もう少し深く掘り下げたアイコンフォントのお話をしたいと思います。
そもそもアイコンフォントって何なの?
アイコンフォントを分かりやすく説明しますと、 「機能のいっぱいある、アイコン集のフォントをブラウザ上で動かす」という事です。 これだけだと、まだ分かりにくいので、 まずはOpentypeというフォントの形式を説明します。
Opentypeとは……
Opentypeには、リガチャー(合字)、スウォッシュ(単語の頭や末にアクセントをつける)、分数など様々な機能があり、 これを使うと、ただキーボードで入力した文字がプロフェッショナルの組版に変わるのです。 リガチャーを例に上げますと、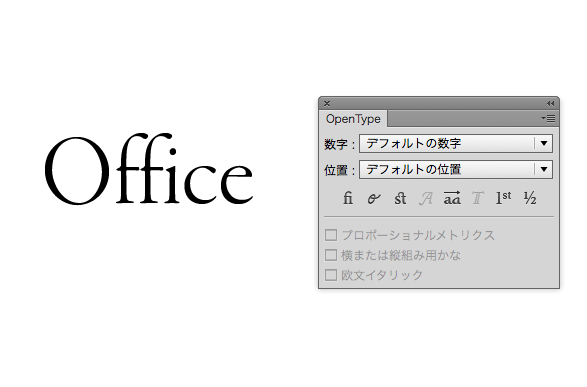
例えば「Office」という文字を入力します。(illustrator CC、Adobe Garamond Premium proを使用)
欧文合字機能をONにすると……
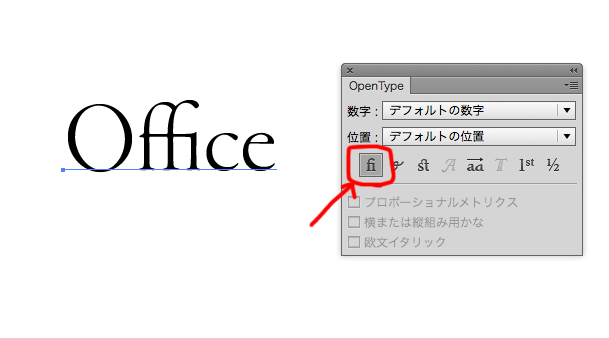
Officeの「ffi」の部分が、1文字になりました。 これは、フォントの作り手側が意図的に「f」と「f」と「i」が入力された場合に1文字の「ffi」に変換しているのです。 fiやflの黒く中途半端な部分をなくし、本文を読みやすくさせるためです。
さて、これからアイコンフォントの話に移ります。今までの「ffi」を応用したのがアイコンフォントです。僕のよく使っている「Symbolset」のサイトです。
アニメーションの文字の部分をクリックするとテキスト入力に切り替わります。 この状態で「love」とキーボードで入力して下さい。

すると、「l」、「o」、「v」とここまでは、普通のテキストなのですが、
最後の「e」を入力すると「♥」になりました。

これがアイコンフォントの使い方です。
まとめ
【メリット】
- 画像の代わりにテキストを入力しているので、SEO的に良い。
- ビットマップの画像データではないので、拡大縮小しても汚くならない。Retinaもバッチリ。
- CSSでの色の変更や装飾も自由自在。
【デメリット】
-
IEでもWebフォントを読み込めますが、クロスブラウザでつかうには、
様々な種類のアイコンフォント形式を読み込まないといけない。
また、僕は正しい使い方ではないのですが、アイコンフォントを通常のフォントとしてインストールし、 カンプデザインにも使ったりしています。
こうする事で、いちいちアイコン集を探す手間が省けるので、 重宝しています。 ただし、この場合は画像ファイルになってしまうので注意が必要ですね。
機会があれば是非お試しください。