こんにちは。システム部の鈴木です。
先日、新年会で肥ったといじられました。暖かくなってから本気出します。
以前書いてからだいぶ間が空いてしまったCodeIgnitorを使って早速社内向けのサービスを作ってみました。
今回はそのときに気がついた点とか書いていこうと思います。


こんにちは。システム部の鈴木です。
先日、新年会で肥ったといじられました。暖かくなってから本気出します。
以前書いてからだいぶ間が空いてしまったCodeIgnitorを使って早速社内向けのサービスを作ってみました。
今回はそのときに気がついた点とか書いていこうと思います。
Android開発が久々すぎてテンパッてる状態のシステム部中村です。
昔からAndroidアプリの開発は、Verの違いで作り方と仕様が色々変わったり、機種によって違いがあったり、エクリプス上でのGUIの作りこみがわかりにくいなどであまり手を出したくなったのですが、お仕事なので、がんばってます。
といいながらAndroid開発で詰まったので、ブログを書くことで気分転換!!
さて、本日お問合せフォームの新設を病院チームからお願いされたので、ささっと片付けるつもりが、
デバック作業中に、なぜかIEでhistory.back()を使ってページ繊維すると(戻る)と入力されていたフォームが空になるという症状を発見。
よくよく調べてみるとIEのタブブラウザー化してから良く出る症状のようでした。
HTMLのキャッシュ設定を正しく指定していないと、空白になるようです。
症状の発生に関しては
1:inputフォームに値を入れる
2:submit で次の画面へ移動する
3:history.back()で前のページに戻る
結果:入力した内容が消えて空になっている
という流れなのですが、 FireFoxやchorome では発生しない現象なので、見落としやすい落とし穴です。
対処方法は
メタタグに
<meta content="86400" http-equiv="Expires" >
このタグをいれて明示的にキャッシュさせてやれば、OKです。
これで、症状が改善されました。
history.backを使わなければいいのですが、どうしても使用する際は症状が現れる前にタグを打っておくことにしておきます。
ディレクターの武士です。
コーポレートサイトを制作させていただいていると、「PDFファイルを検索結果に表示させたい」「PDFが検索結果に出ないようにしてほしい」などのご要望を承ることがあります。
今回はPDFファイルのSEOについて解説します。
■PDFファイルは検索エンジンに認識される?
サーバにアップされたPDF文書は、基本的にHTMLと同じように検索エンジンにインデックスされます。
検索される内容は文書内の文字列(テキストコンテンツ)およびメタデータです。
文書内の画像は認識されないようです。
■PDFファイルのSEO対策
PDFファイルはそのままサーバにアップしても検索エンジンにインデックスされますが、よりSEO対策を強化するには下記の2つの方法があります。
(1)文書のプロパティ(メタ情報)を設定する
Adobe Acrobatの場合、ファイル→プロパティを選択すると「文書のプロパティ」編集画面になります。
「概要」タブで、タイトル、サブタイトル、キーワードを設定することで、検索エンジンに最適化されたPDFを作成することができます。
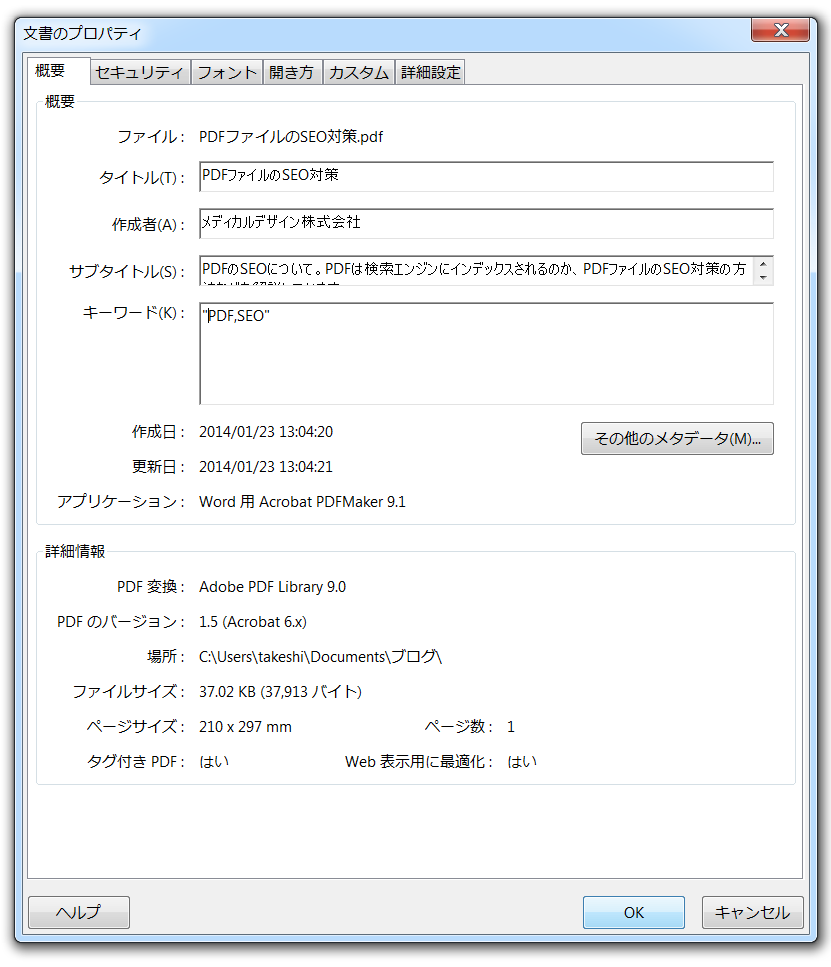
タイトル:HTMLの<TITLE>タグと同じ扱いになります。検索結果のタイトル(リンク部分)として表示されます。
サブタイトル:HTMLの<meta description>と同じ扱いになります。検索結果のスニペット(説明文)として表示されます。
キーワード:HTMLの<meta keywords>と同じ扱いになります。HTMLと同じように5個程度設定するのが良いかと思います。
※PDFのプロパティを編集するにはAdobe Acrobatなどの専用のソフトが必要です。
(2)リンク元のアンカーテキストを最適化する
Googleの公式見解によれば、検索結果に表示するタイトルの生成には、前述のファイル内のタイトル(メタ情報)と、“PDFファイルを指すリンクのアンカーテキスト”の2つの要素を使用しているとあります。
“PDFファイルを指すリンクのアンカーテキスト”とはどういう意味かというと、
PDFへのリンクテキスト(またはボタン画像等のALT)が「会社概要はこちら」の場合、検索エンジンに「会社概要がこちら」というタイトルでインデックスされる可能性があるということです。
SEO対策したいキーワードが「メディカルデザイン」「会社概要」の場合は、「会社概要はこちら」ではなく「メディカルデザイン会社概要はこちら」というアンカーテキストでPDFにリンクを設定するのが正解ということになります。

PDFの編集ソフトがなくて(1)の作業が不可能な方は、(2)だけでも対策しておくことをお奨めします。
■PDFを検索結果に表示させない、検索結果から削除するには
個人情報など、PDF文書内に検索されたくない内容が記載されている場合は、検索エンジンにインデックスされないよう対策する必要があります。
簡単な方法としては、PDF文書をパスワードで保護する、または暗号化することでクローリングを回避することができますが、ユーザライクな方法ではないのであまり現実的ではないでしょう。
ではどうすれば良いかというと、PDFファイルのクローリングは、.htaccessで制御することができます。
X-Robots-Tagという記述を用います。
・サイト内にあるすべてのPDFドキュメントを検索結果に表示させたくない場合
<Files ~ "\.pdf$">
Header set X-Robots-Tag "noindex"
</Files>
・「ファイル名.pdf」を検索結果に表示させたくない場合
<Files ファイル名.pdf>
Header set X-Robots-Tag "noindex"
</Files>
・「ファイル名.pdf」のクロールとインデックスを、2014年2月1日0時以降に終了させたい場合
<Files ファイル名.pdf>
Header set X-Robots-Tag "unavailable_after: 1-Feb-2014 00:00:00 JST"
</Files>
SEOに詳しい方ならお気づきかと思いますが、要はHTMLのヘッダーに記述するrobot metaタグや、robot.txtの記述方法(と概念)とほぼ同じです。
PDFの場合はmetaタグを埋め込むことができないので、 X-Robots-Tagを.htaccessに記述することで検索エンジンのクローラーを制御します。
既にインデックスされてしまっているPDFファイルを検索結果から削除したい場合も、X-Robots-Tagで指定すれば認識してもらえます。
ただ、おそらく一定の時間はかかると思いますので、急ぐ場合はGoogleウェブマスターツールのURL削除ツールも併せて使用することをおすすめします。
初めまして。デザインや写真の担当をしております梶岡です。
このブログではPhotoshopやIllustratorなどのネタを今後担当していこうと思います。
さっそくですが、一眼レフをお持ちの方、
大量のRAWデータを現像する際はどう対応されているでしょうか?
私がまだ趣味レベルだった頃は、一枚一枚Photoshopのプラグインである"Camera raw"で現像していましたが、
そのやり方では途方もなく時間がかかってしまいます。
モノによっては1000~2000枚程の画像の処理をしないといけない場合がありますw
一枚ずつしか処理できない!
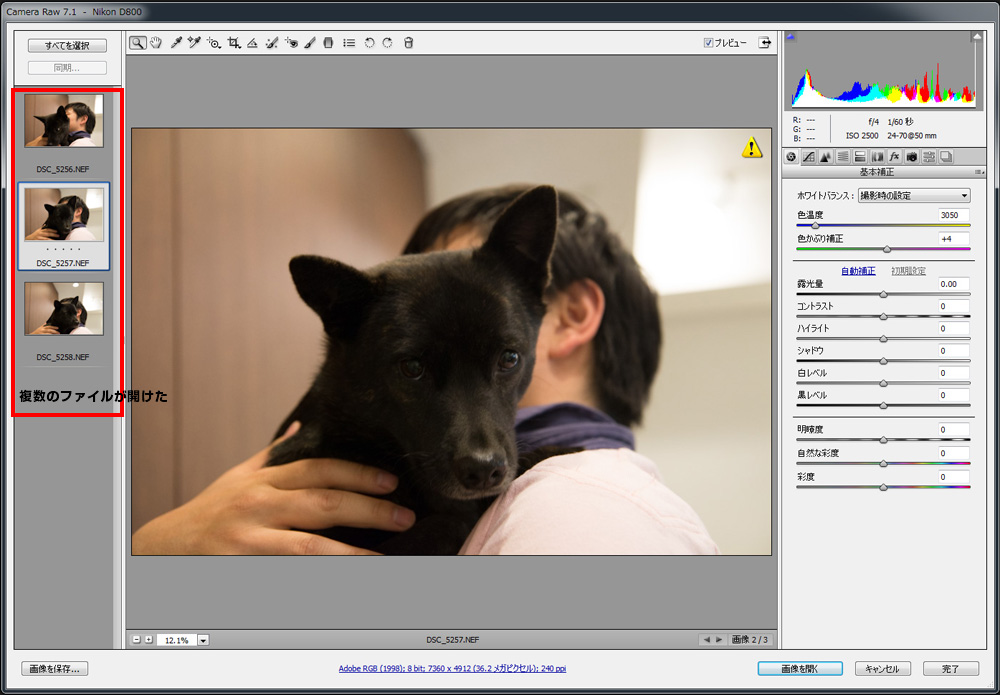
「まとめていっぺんにraw現像をしたい!」というときは
Photoshopを立ち上げて、「ファイル/開く」で複数選択すればOKです。

今回はちょっと青めに修正してみます。
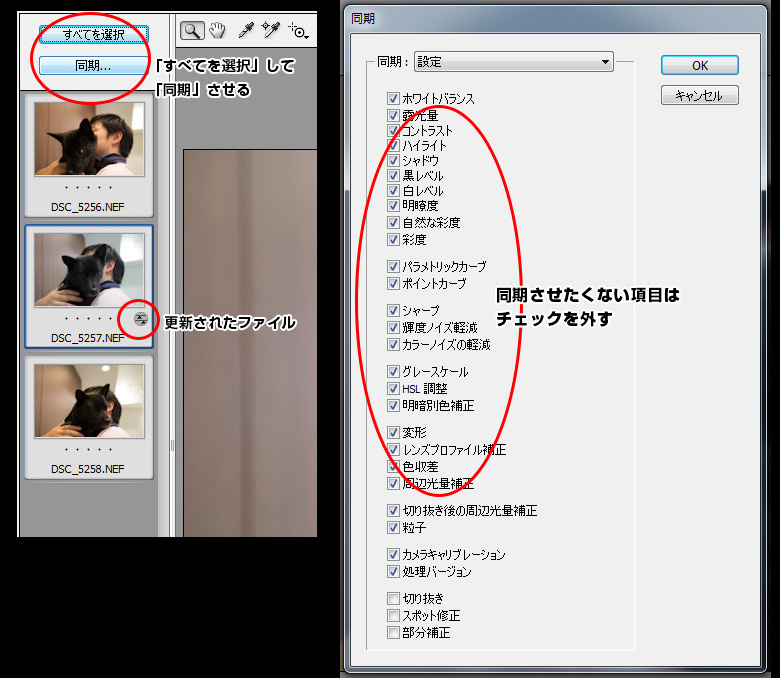
他の写真も同じ修正を反映させるには、「すべてを選択」して「同期」させます。
チェックボックスで反映させる項目を個別に指定することも可能です。
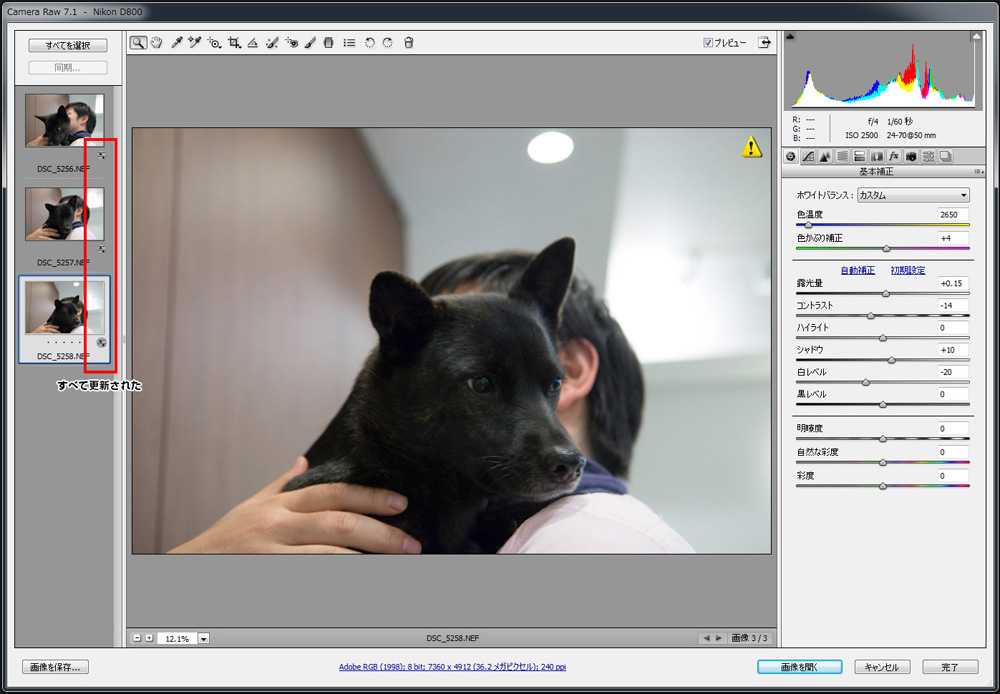
同期させて他の写真も青く修正されました。
あとは左下の「画像を保存」をクリックすれば一気にjpgに書き出されます。
しかしこの処理には問題があり、
枚数によっては1時間以上Photoshopが使えなくなります。
そんな時、いらない子扱いされがちなAdobe Bridgeが大活躍です!
Bridgeの主な機能は、画像を一括で確認したり比較したりできる管理ツールのようなものですが、
Photoshopの代わりにCamera rawを立ち上げることが可能なのです。
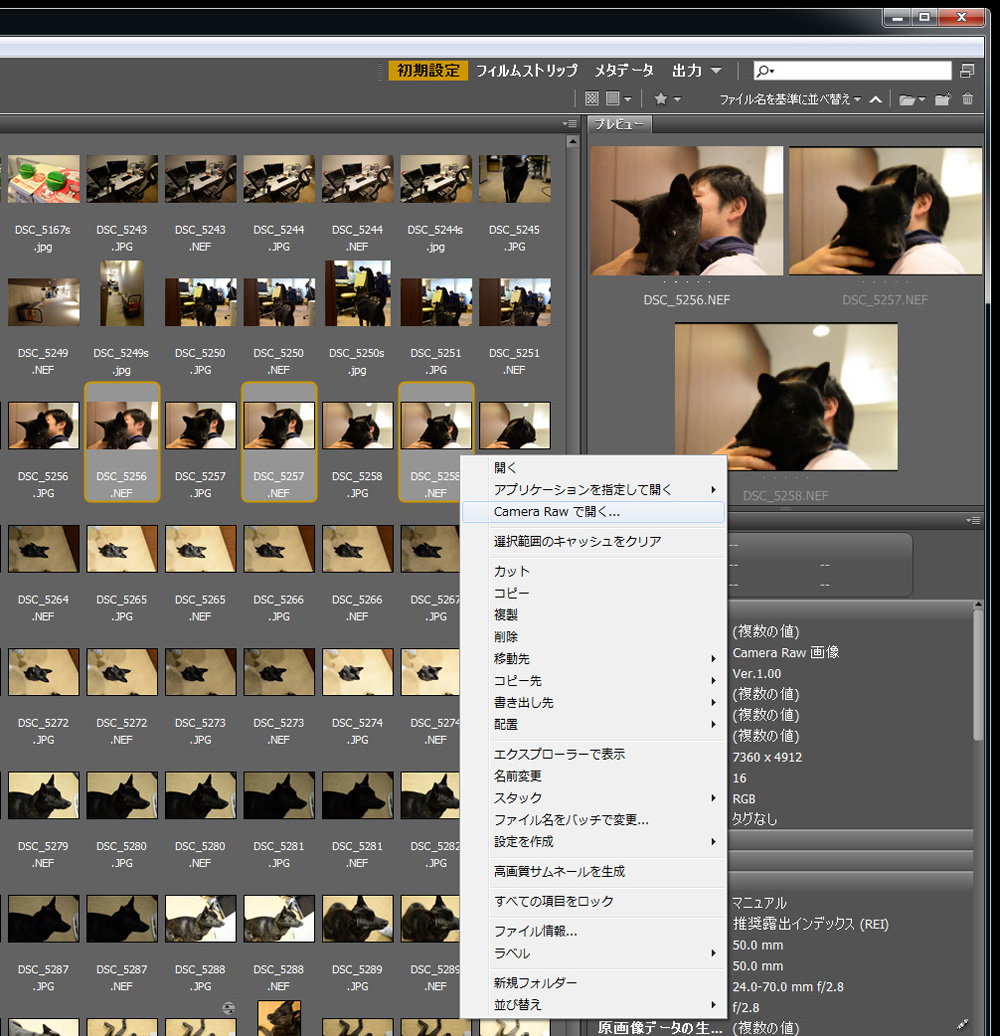
複数選択してCamera rawを押すだけ。
PhotoshopとBridgeを併用して交互に作業することで、
ノンストップでraw現像が可能になります。
ただし、PCにはものすごい負担を与えるのでクラッシュにはご注意を。。
システム部の中村です。
Xcodeでの開発を行う際、iOS7からステータスバーの一判断がiOS6と大きく変わっており、
iOS6と7を共通のストーリーボードで開発する際webviewなどのオブジェクトがステータスバーにかぶさるという自体が発生します。
OSのVerを判断して位置を移動させるコードで逃げている方もいますが、極力コードには手を出さないように書きたい自分は
下記のようなやり方で逃げています。
iOS6/7 Detail にステータスバーの20PX分マイナス値を与えてやるという方法です。
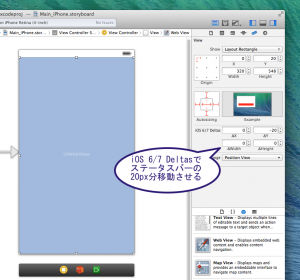
iOS6/7 Detail とは iOS6の場合どのくらいストーリーボードで設定した位置から動かしますか?という場所なので
ここに、-20を与えるとよいわけです。
ようはこのiOS6/7のY軸を-20pxと指定することで、iOS7の場合だけ位置を動かしてくれるようになります。
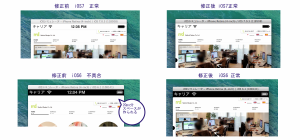
結構検索してみると皆さんあまりここを使われていないようでして、、layoutで強制していたりする方もいますが、これが一番簡単ではないかなと思います。
IE11がWindows7などでも使えるようになって、早2ヶ月を過ぎようとしております。
ちらほらと今迄動いていたJSのプログラムが動かない・動作が不安定など色々と問題が発生しているようですが、みなさんはいかがでしょうか。
特にIE11からユーザーエージェントも変更となりUAでプログラムのフローを制御している場合などは必ず問題が発生するのではないでしょうか。
ロジックもIE11からIE10からかなり変わっておりjavascriptの動作に関しても大幅に変わっています。
IE11の大きな変更点としてまとめると
1 ユーザーエージェントの変更
2 JavaScriptで取得可能なブラウザー名の変更
3 ドキュメントモード(描画エンジン)の変更
ではないでしょうか。
現在開発中の自社プロジェクト向けにグラフを出力する箇所が発生しそうだったので、少しばかり調べてみるとFLASHを使わずにグラフを生成できるライブラリーを発見
Flotr2 ダウンロード先: http://humblesoftware.com/flotr2/
少しいじってみましたが、思いのほか使いやすいです。
何より公式のサンプルが多いので、そのままどおりにコピペして数値をPHPなどで変換してやれば色々できますね。
その上わかりやすいサンプルとなっており、プログラムが苦手なコーダーさんでも対応できそうです。

昔はグラフを表示する場合は、ほとんどの場合でFLASHにデータを送りFLASHによって表示させていましたが、ほんと世の中便利になる一方ですね。
ただ IE11ドキュメントモード: Edge の場合で小さな不具合を見つけたのでアップデートを待ちたいです。
ちなみにすでに自社で動いているアクセス解析ツールにも利用できるのではないか!そうすればスマートフォン対応(タブレット含む)も可能だし・・
今度時間を作って埋め込み実験等やってみたいな。